前言
压缩与解压的另一种说法就是,压缩相当于对文件的加密过程,解压相当于对文件的解密过程,比如说,盲-z,僧-w,那么盲僧-zw,当然加密与解密各种各样,不一定非是字符型的
压缩对比
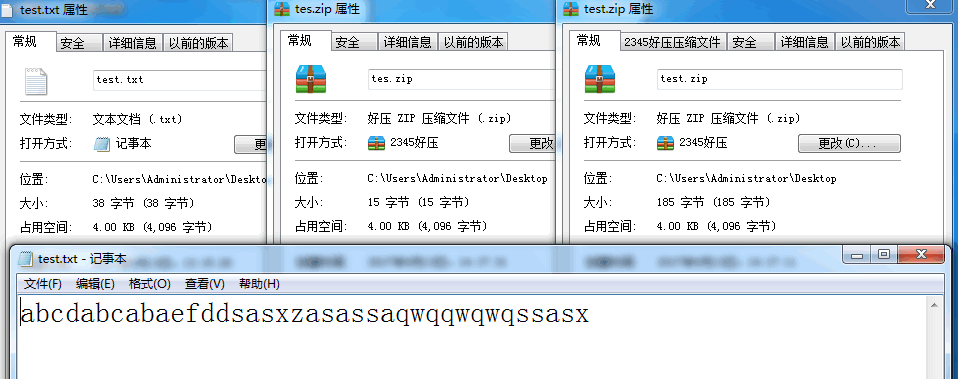
如图,最左边是未压缩的原始txt文本文件,里面有38个字节,所以占38字节,中间是利用哈夫曼编码压缩的,居然只占15个字节,最右边是好压自带的压缩,占185个字节,通过对比,发现哈夫曼压缩居然节约这么多空间!
压缩原理
计算机只能存储二进制数,即非0即1,比如刚学c语言那会接触到的ASCII码,它是专门处理英文的,比如一个字节占8位(由8个01串组成)来表示各种英文字母以及符号,比如0在ASCII编码的十进制表示是48(00110000),a是97,所以英文共有2的8次方个,但是汉字远远不止256个,所以一个汉字用两个字节表示,所以共有2的16次方汉字,而汉字编码一般用UTF-8和GBK等
存储过程
比如在文件中存储aaabbc,理论上占6个字节,并且存储的二进制为01100001(a)01100001(a)01100001(a)01100010 (b)01100010 (b)01100011 (c)那么哈夫曼是怎么存储该数据的了
它是根据某个字出现的次数,比如a出现3次,b出现2次,c出现1次,将次数作为相应字的权值来构造哈夫曼树的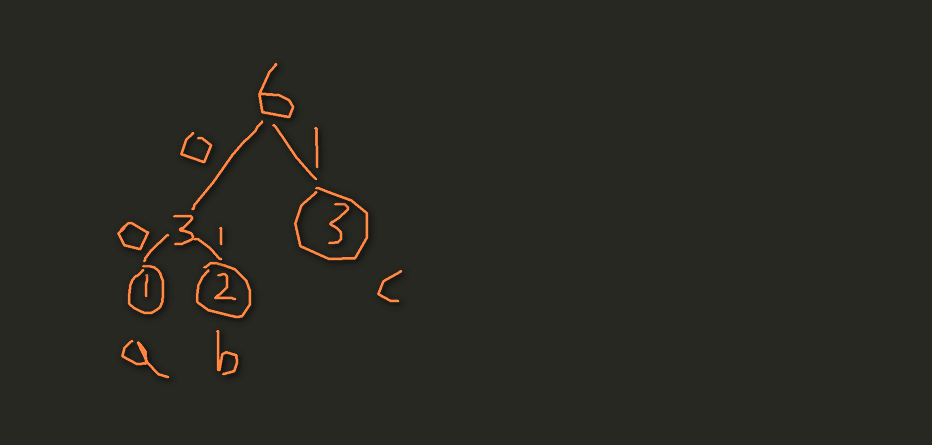
所以得到:哈夫曼编码为a(1),b(01),c(00),所以的到压缩后的编码为aaabbc(111010100),注意这里变成2个字节了,然后将该二进制转换成10进制就行了
压缩实现
一般有以下步骤
1.读取文件,统计文件中每个字节出现的次数,将该次数作为权值
2.根据权值构建哈夫曼树
3,根据哈夫曼树构建码表
4在读取文件,通过码表对文件中读取的字节进行加密处理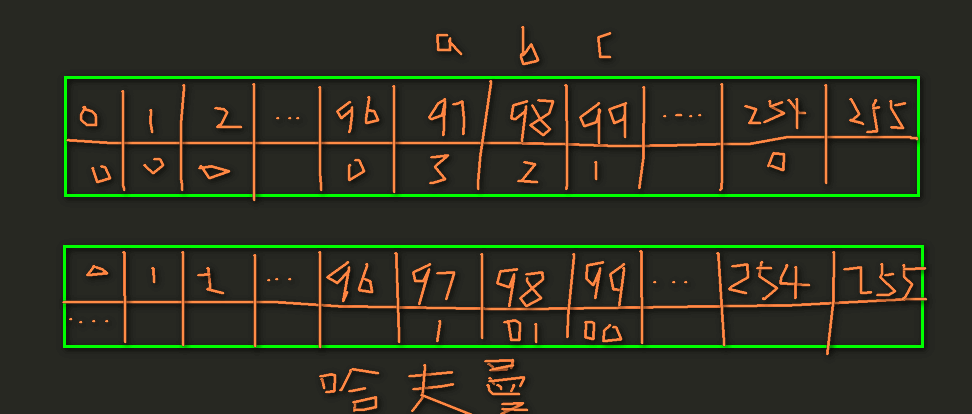
在这里定义了一个256的整型数组(存取次数作为权值)和一个256的字符串数组(存取哈夫曼编码值)
码上有戏
哈夫曼结点
与之前不同的是增加了索引,便于搜索
压缩实现类
这里有几处需要注意下,首先changeStringToInt(String s)方法是根据二进制的定义做转换的,void countTimes(String path)throws Exception中那个value是根据其相应的字节的ASCII码值得,比如a是97,就是times[97]++,初始值都是0;
然后void compress(String path,String destpath)throws Exception中读文件刚开始是取8位然后转成int在写进文件,然后取第8未到末尾,在循环直至最后不足8位,在后面补0,在写进去。
测试类
结果:
1011010101110010110101011011011011100111011110011000010000100111010100010000010011111101101111110111111011000010000100
同时会生成一个压缩文件,如前面的图所示
解压
解压原理
之前说过哈夫曼编码不会出现像0和01这样前者是后者子串的情况,所以解压采取的办法就是在压缩时写进去每个编码的长度和对应的编码,就像密码本一样,记录着每个密码的详细信息(这里理解每个密码长度和密码数据域唯一确定一个解码)
打个比方,假设ab压缩后为0和10,当然压缩后是变成010,那怎么解码了?,首先在压缩时,在之前压缩代码上加上一个记录编码长度和对应的编码,像a不是97吗,那在写入时记录code[97]=1,对应的编码str[97]=0,code[98]=1;str[98]=0,一次类推,写入时是先写入编码长度的,不过要将字符串转换成十进制,然后通过字符串分割成不同编码,这样每个字节也就拿到手了
模拟一下,不妨把abbcc先压缩,然后读出它的二进制如下
000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000021200000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000015214308
再来分析分析:
前面在152之前都是存取密码长度的信息,212是对应ASSII码的相应字节的编码长度,如a(10)、b(0),c(11)所以长度分别对应212,接下来就是152也就是abc的二进制值了,10011,不足8位后面补0,即10011000,对应十进制就是152,后面143就是文本的需要解密的编码,后面08没有弄懂,在压缩文件中并没有输入这个东西,也做了大量实验发现都有后面这些数字,暂且认为就是压缩文件自带的标识吧(逻辑上还没有证明,所以勉强这么认为)
所以,解码思路就是先根据长度读取相应位置,然后分割每个位置得到相应二进制编码,最后再转回来,看看编码的打印结果
0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000212000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000codeLength:1
int152
哈夫曼编码:10011000
huff10
huff0
huff11
需要解密的字符串:10001111
截取的字符串:10
截取后剩余编码长度:6
截取的字符串:0
截取后剩余编码长度:5
截取的字符串:0
截取后剩余编码长度:4
截取的字符串:11
截取后剩余编码长度:2
截取的字符串:11
截取后剩余编码长度:0
不是很规范,但是大概跟踪了过程,长度为5(10011),不足8位不以为,所以codeLength为1,152就是哈夫曼密码手册值了,变成二进制为10011000,然后分割成10,0,11分别对应ASSII码为a、b、c三个字符,需要解密的是10001111,也就是143,解密分别对应abbcc,所以至此完成解密了
说了这么多,再来看看代码吧
码上有戏
压缩编码
由于解压需要的压缩编码在之前主要修改一点,所以这里就把增加的代码贴出来,分析分析
上面代码是说首先我们已经统计了文本中字符出现的次数,压缩那里已经写过了,然后将长度表写入进压缩文件,也就是那一大串000中间含有长度的字符串,存在code里,注意长度为空就是空字符,所以code就是那5位的二进制,然后不足8位的补成8位,再变成十进制也就是152了,这是这段代码与之前增加的部分,我们也称为码表构造
解压实现类
这里的codelengths[]和codeMap[]就是分别存放码表和码表值的数组,流程就是先读取文本内容,拿到长度表中有长度的编码,如212,然后判断其是多少个字节,然后读哈夫曼编码,根据字节数,转成二进制后,找到对应的码表,然后就是分割编码了,最后就得到我们想要的解码了。最后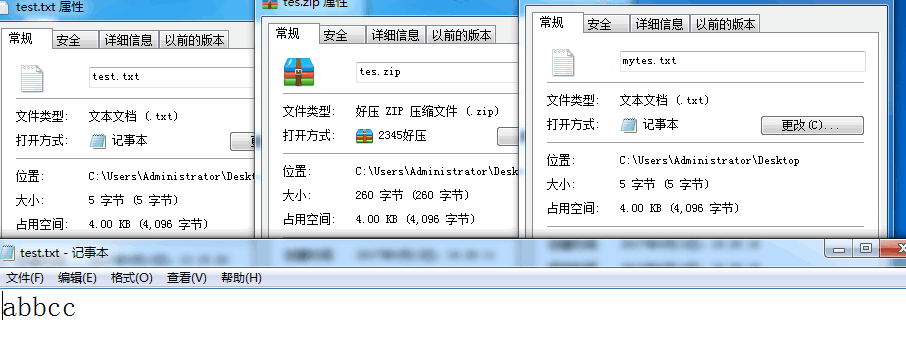
分别为压缩前,压缩后的,会发现压缩居然比压缩前占得空间还大,那是因为我们压缩的文件太小了,而之前也比较过了,压缩一般都是针对大文件的
总结
最后不得不说哈夫曼树的精妙让人惊叹和着迷,同时也认识到了计算机底层知识的重要性,当你回过头来再去看以前的知识,会有另一种不同的感受,当然当再去看压缩与解压,原来是这么回事。当然探索的过程是很累的,会遇到各种难题和挫折,而在当下这个追求功利主义,很多时候都是表象的去用一些东西,当然有时候你把时间花在一些与收益不是很正相关的上面,可能会让你的性价比不是很高,但是正是由于这种自娱自乐的快乐,才更让人充实,而不是每天都去追求“外功”。