前言
说到哈夫曼树,就不得不说它在压缩与解压方面的应用太完美了,就是把一个大的文件,通过算法压缩成一个较小的文件,从而大大节约了空间
哈夫曼树
通俗的说就是给定n个权值作为n个叶子结点,构造一颗二叉树,若带权路径长度达到最小,称这样的树为哈夫曼树,也称为最优二叉树,同时,由定义可知,哈夫曼树是带权路径长度最短的树,所以权值较大的结点离根较近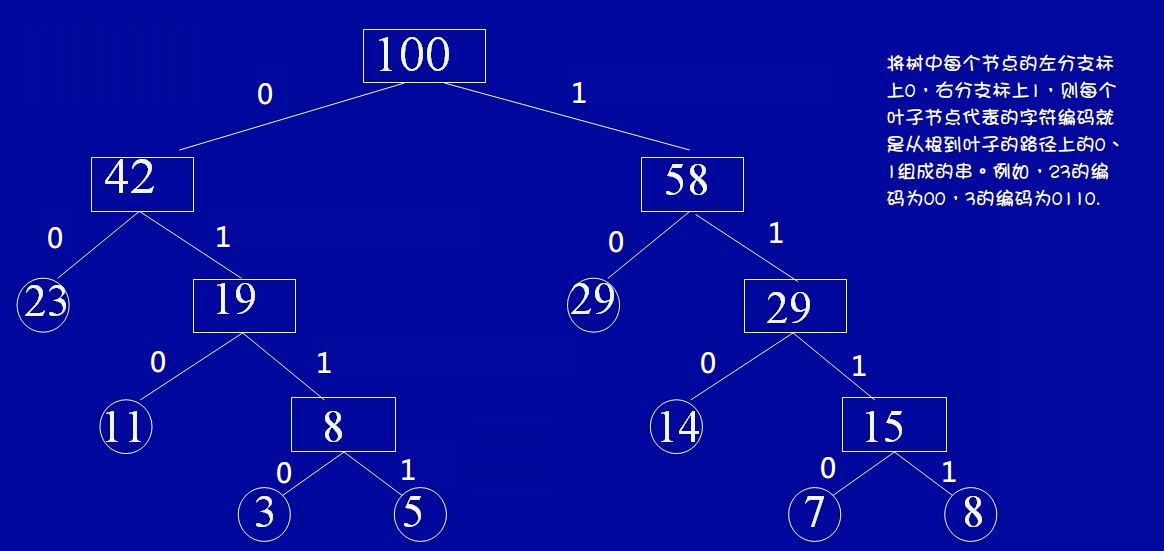
相关术语
路径长度
结点路径长度:从树中一个结点到另一个结点之间的分支,构成两个结点之间路径,路径上的分支数目称为结点长度,如结点100到结点29的结点路径长度就是2
树的路径长度:从树根到每一个结点的路径长度之和
权值
所有叶子结点的date域,也就是当前叶子结点存放的数据域
带权路径长度
结点带权路径长度:从该节点到树根之间的路径长度与结点上权值的乘积
树的带权路径长度:树中所有结点的带权路径长度之和,并且几位WPL,如果WPL最小,则称该二叉树为哈夫曼树
哈夫曼树构建过程
它的构建思想其实很简单的,大概如下
1.根据给定的n个权值{w1,w2,..wn}构成n棵二叉树的集合F={T1,T2,..Tn};其中每棵二叉树Ti中只有一个带权为wi的根结点,器左右子树为空
2:在F中选取两颗根结点权值最小的树作为左右子树构造一颗新二叉树,并且新二叉树的根结点权值为左右子根结点的权值之和
3:在F中删除这两颗树,同时将新二叉树加入F中
4:重复2和3步骤,知道F中只含一棵树为止
构造哈夫曼树
哈夫曼结点
构造哈夫曼树
其实这段代码就是上述四个步骤的实现,代码也很好理解,带权值为datas,将结点放到链表中,然后注意利用非正规的选择排序将链表集合里权值从小到大排好序,然后开始选择权值最小的两个构造一个新的权值结点,同时删除那两个,加入这个新的。。重复直到只剩一个根结点为止,很明显此时就是哈夫曼树了,最后通过后序遍历得到哈夫曼编码值,这里我们约定左子树一个路径为0,右子树一个路径为1,所以一定不存在像01与010这样前面是后面子串的编码值
测试类
结果:
8:000
11:001
23:01
14:100
7:1010
3:10110
5:10111
29:11
注意这里的结果和图示有一个地方不一样,就是那个几点8,这里的结点8是合成的,可以根据结果画出哈夫曼树,比较就会看出不同