前言
留言版的设计本质就是树结构的设计留言版设计(旧),之前的设计是从模仿B树写的,发现在数据存取时有一些需要优化,所以优化了下表结构和数据存取。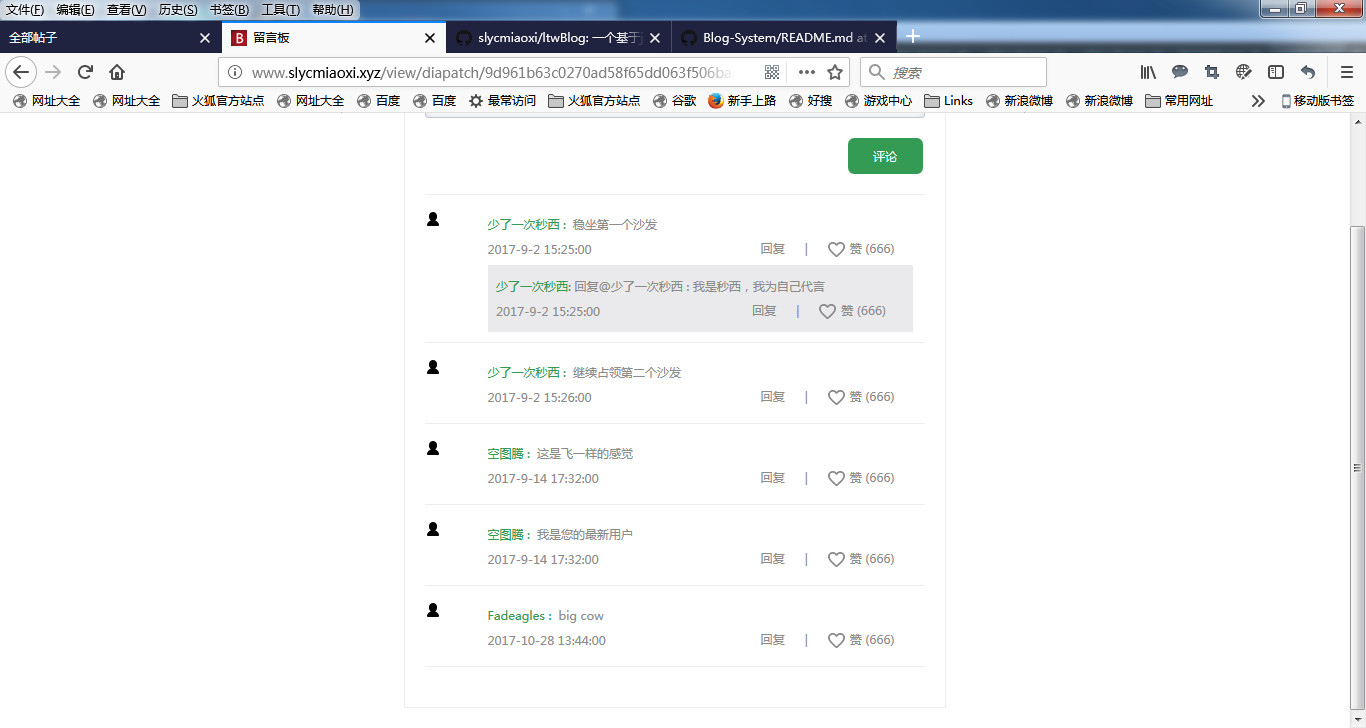
数据库设计
为了方便直接贴出截图(以下是按照自己的想法建的结构,仅作为项目说明,如不合理,请谅解)
直接设计一张数据结构表t_message_info,其中parent_node为父节点编号,如果为0,表示为顶层留言,无父节点,否层则是孩子结点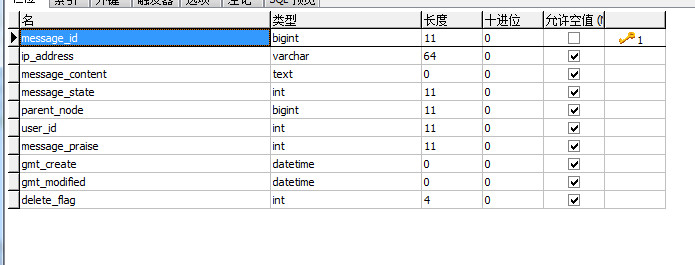
而其大概流程就是页面加载留言
父-子结构dto建立
在旧版本基础上优化了数据结构之后,就可以直接建立dto,在里面套一个子dto集合,并且重新equals和hashcode,最后只要去dto集合数据,按照父-子集合依次放入即可,而不需要兄弟结点了
取出数据
由于重写了equals和hashcode,就可以直接通过messageId得到父节点。大概流程就是取出留言数据->分类(所有父,所有子集合)->遍历子集合,依次放到父节点
不足之处
前端由于短板,主要为数据加载趁现在页面初始化中,并且是通过动态语句创建div,所以分页没弄出来,导致数据量大会出现问题