前言
不知不觉,从九月份后就已经很少写博总结了,有点小颓废了。好吧,回到正题,本着应用为主,了解原理为辅的原则总结。
以我的微型论坛中的文章内容检索为例作为应用网站链接
全文检索定义
全文检索首先对要搜索的文档进行分词,然后形成索引,通过查询索引来查询文档,比如:字典
字典的偏旁部首页,就类似于luence的索引
字典的具体内容,就类似于luence的文档内容
同时,Lucene是一个工具包,它不能独立运行,不能单独对外提供服务。说白了,就是几个jar包
Lucene实现全文检索的流程
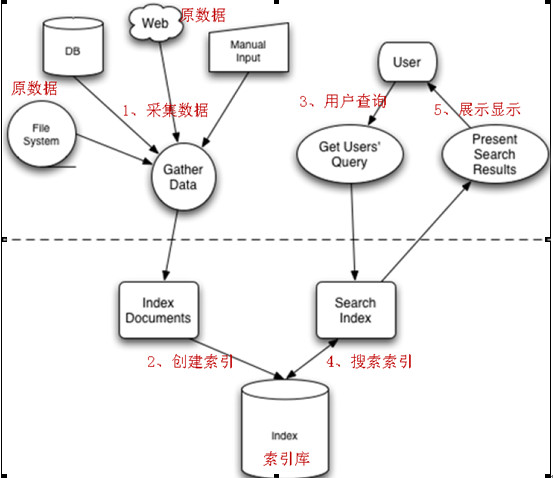
其主要分为索引流程和搜索流程
索引流程:采集数据—文档处理-存储到索引库中
搜索流程:输入查询条件—通过lucene的查询器查询索引—从索引库中取出结果
码上有戏
需求:对进入论坛的所有文章进行全文检索
首先我们利用jdbc采集数据库,为了方便直接利用中文查询器,只贴出核心代码
下面是其实现类
索引文件的逻辑结构
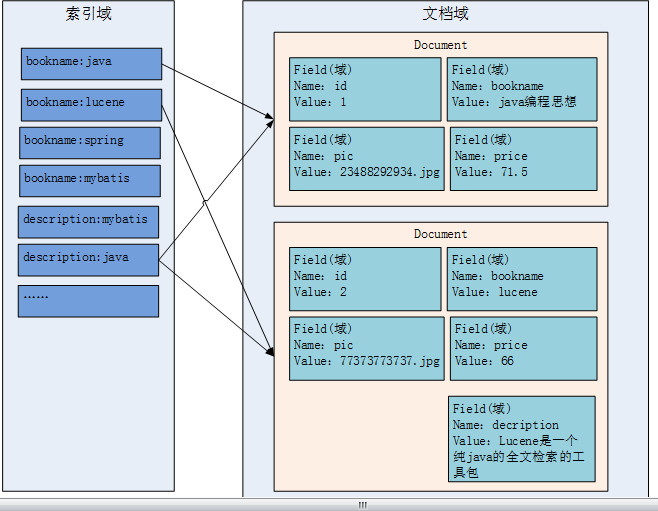
通过图示,可以发现最重要的就是文档域和索引域
文档域存储的信息就是采集到的信息,通过Document对象来存储,具体说是通过Document对象中field域来存储数据。
比如:数据库中一条记录会存储一个一个Document对象,数据库中一列会存储成Document中一个field域。
索引域主要是为了搜索使用的。索引域内容是经过lucene分词之后存储的(这里的分词根据所引入的分词器不同,分词效果不一样)
传统方法是先找到文件,如何在文件中找内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大就搜索慢
但是lucene采用倒排索引结构,它是在索引中匹配搜索关键字,由于索引内容量有限并且采用固定优化算法搜索速度很快,找到了索引中的词汇,词汇与文档关联,从而最终找到了文档。
创建索引
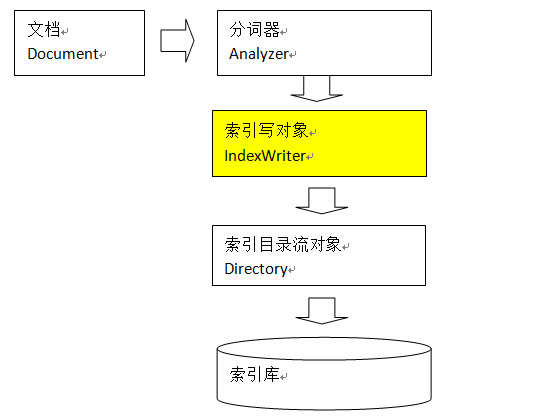
其中,IndexWriter是索引过程的核心组件,通过IndexWriter可以创建新索引、更新索引、删除索引操作。IndexWriter需要通过Directory对索引进行存储操作。
Directory描述了索引的存储位置,底层封装了I/O操作,负责对索引进行存储。它是一个抽象类,它的子类常用的包括FSDirectory(在文件系统存储索引)、RAMDirectory(在内存存储索引)。
分词
Lucene中分词主要分为两个步骤:分词、过滤
分词:将field域中的内容一个个的分词。
过滤:将分好的词进行过滤,比如去掉标点符号、大写转小写、词的型还原(复数转单数、过去式转成现在式)、停用词过滤
停用词:单独应用没有特殊意义的词。比如的、啊、等,英文中的this is a the等等。
搜索流程
Field的属性,主要有三个
是否分词(Tokenized)
是:对该field存储的内容进行分词,分词的目的,就是为了索引。
是否索引(Indexed)
是:将分好的词进行索引,索引的目的,就是为了搜索
是否存储(Stored)
是:将field域中的内容存储到文档域中。存储的目的,就是为了搜索页面显示取值用的。
创建查询对象的方式
通过QueryParser来创建查询对象(其他方式就不介绍了)
通过QueryParser来创建query对象,可以指定分词器,搜索时的分词器和创建该索引的分词器一定要一致。还可以输入查询语句。
查询语法
1、基础的查询语法,关键词查询:
域名+“:”+搜索的关键字
例如:content:java
2、范围查询
域名+“:”+[最小值 TO 最大值]
例如:size:[1 TO 1000]
3、组合条件查询
条件1 AND 条件2
条件1 OR 条件2
条件1 NOT 条件2
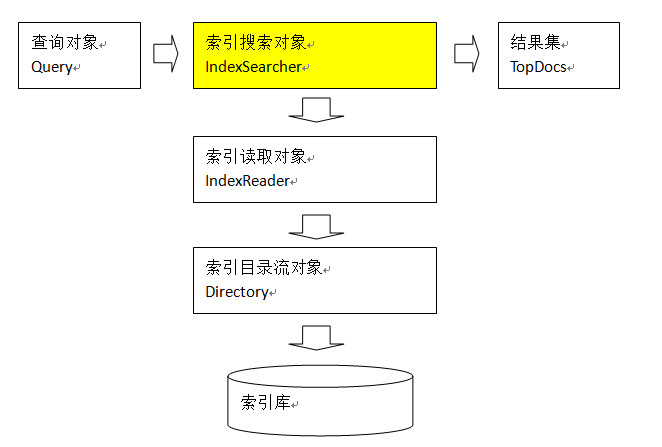
TopDocs
Lucene搜索结果可通过TopDocs遍历
earch方法需要指定匹配记录数量n:indexSearcher.search(query, n)
TopDocs.totalHits:是匹配索引库中所有记录的数量
TopDocs.scoreDocs:匹配相关度高的前边记录数组,scoreDocs的长度小于等于search方法指定的参数n
总结
当然lucene的知识体系远不止这些,这里只是通过应用主导学习来浅尝全文检索。