前言
图是数据结构中最复杂的,正是因为它的复杂,它也是最优魅力的。当然图的存储结构有多种方式,最常用的就是邻接矩阵和邻接表。为了方便,这里图的遍历使用邻接矩阵表示
邻接矩阵

如图,这里只画了无向图,其中顶点由一个一维数组表示,一个二维数组存储图中的边或弧的信息,可以发现无向图是一个对称矩阵,并且约定二维数组arc[i][j]=w,若边(vi,vj)属于该图,arc[i][j]=0,若i=j,否则arc[i][j]=一个无强大值,图中是用1代替了,实际中按上述规则
深度优先遍历
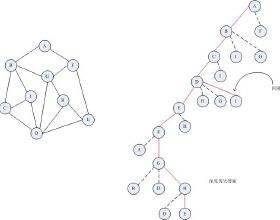
图的遍历就是指从图中某一顶点出发遍历图中其余顶点且使每一个顶点仅被访问一次,然而由于同一个图可能在空间形式上有不同画法,所以造成不能采用之前使用的双亲等方法,所以可以把访问过的顶点打上标记,即设置一个访问数组visited[n],n是图中原点个数,初值为0,访问过后设置为1,这样就可以避免访问重复的了
而深度优先遍历,也叫深度优先搜索,简称DFS,就像在一个房子中搜索一样,从每一个房间开始,而是不留死角的搜索,也就是说该房间内所有地方搜索完,在去搜索其他房间,以此类推
从图中可以发现它是一个递归过程,也就是像二叉树的先序遍历,只不过,已经遍历的结点可以跳过
|
|
为了方便,就创建图的过程写死,最终深度遍历的结果为ABCDEFGHI
广度优先遍历
又称为广度优先搜索,简称BFS,它像二叉树遍历中的层序遍历,也就是一层一层的遍历,如上图,与A相连的有B、F,先遍历,又与B相连的有C,I,G,F相连的有G,E,所以下一层为C,I,G,F,依次类推一层一层遍历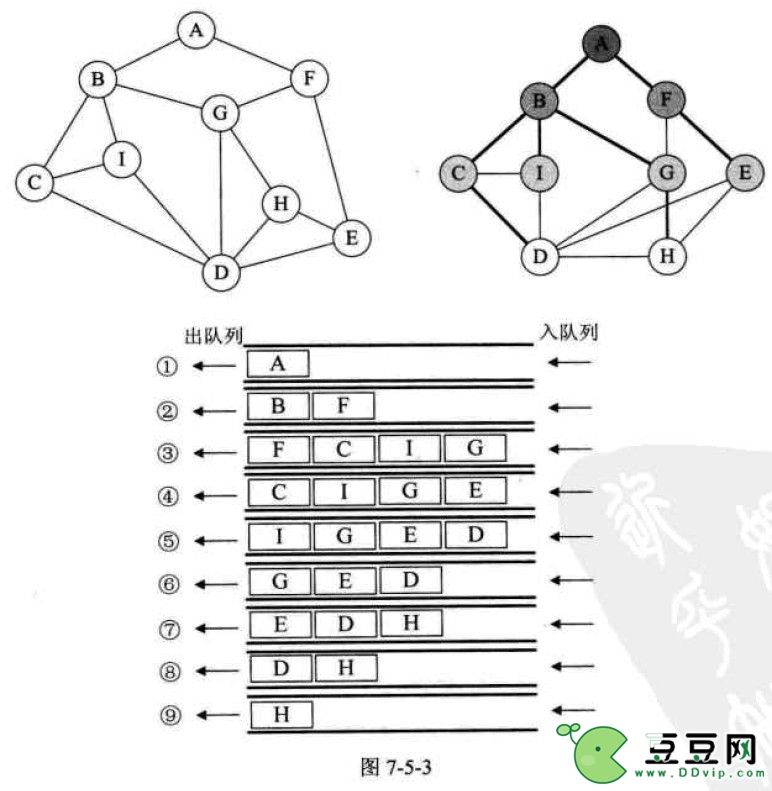
如图它的核心思想就是构造一个队列,每一层的结点,如A出队后,与它相连的下一层结点B、F就要入队开始遍历,然后B遍历完出队,与B相连的下一层结点C、I、J入队,依次类推
队列
广度遍历
最终的结果是
A B F C I G E D H
总结
最后发现深度优先和广度优先遍历的时间复杂度是一样的,他们的适用场景不一样,深度优先更适合目标比较明确,已找到目标为主要目的的情况,而广度优先更适合在不断扩大遍历范围时找到相对最优解的情况