前言
快速排序被列为20世纪十大算法之一,正如其名一样,排序的速度非常快。
而它的基本思想就是通过一趟排序将待排序的记录分割成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续排序,最终达到有序的目的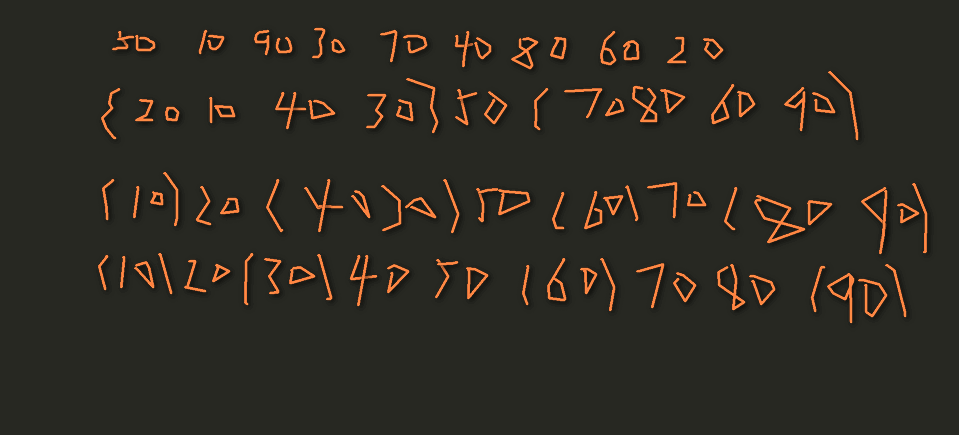
快速排序
采取同样的策略,从计算机的角度看看程序是怎么执行的
里面有个函数Partition(L,low,high),和归并排序一样,暂时先不管它,初始化数组为{50,10,90,30,70,40,80,60,20},初始low=1,high=9;
pivot为选择其中一个关键字,比pivot小的排到左边,比pivot大的排到右边,显然此时pivot=5,然后执行 QSort(L,1,4)直至排好序,同样右边也是递归调用QSort(L,6,9),这里的核心算法也就是Partition(L,low,high)如何排序的了
同样一行一行的看,这里默认选取子表的第一个记录作为关键字pivotkey=L->[low];接下来,由于low=1
最后low=3<9在循环,90>50,满足,high–,high=8,有L->high[8]=60>50;high–;有80>50;high–,有40<50,退出循环,此时high=6,交换,依次类推,最终low=high=5,退出整个循环
最后在分别递归低和高的子表,最后我们发现他的规律如此只简单,遇到比关键字小的,依次递增比较,直到有比它大的,在换另一边比较,不得不说快速排序实在是太精妙了
最后再来看一下快速排序的时间复杂度,在最优的情况下为O(nlogn);
排序算法间的比较
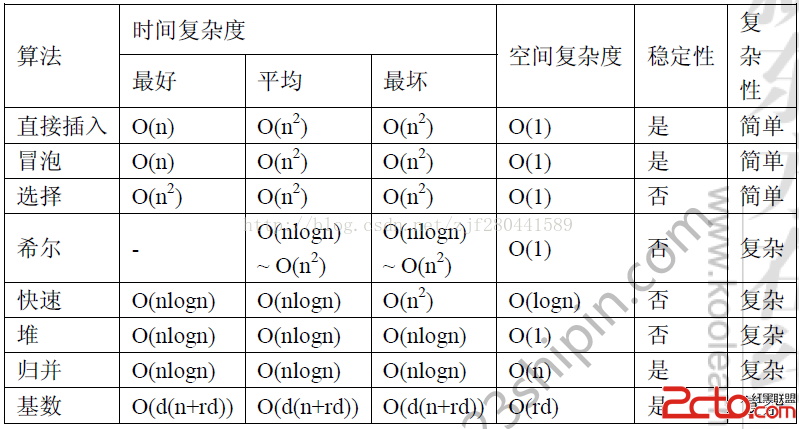
分类