前言
散列(hash)表是一种支持高效的查找、插入和删除操作的数据结构,它是针对查找效率接近O(1)而专门设计的。它根据元素的关键字确定元素的存储位置,而其中主要解决两个问题,设计散列函数和处理冲突
散列函数
在数据元素的关键字和该元素的存储位置之间建立一种对应关系,称为散列函数,而由散列函数决定元素存储位置的存储结构称为散列表,散列函数声明为
public int hash(int key) //散列函数,确定关键字为key元素的散列地址
散列函数实质上是关键字集合到地址集合的映射,如果这种映射是一一对应的,则查找效率是O(1),但是由于散列表是一个压缩映射,即存储容量有限,即映射关系是多对一的映射,所以会产生冲突
冲突
设两个关键字k1和k2(k1!=k2),如果有hash(k1)=hash(k2),即它们的散列值相同,表示不同关键字的多个元素映射到同一个存储位置,称为冲突,如图,所设的关键字序列是(1,4,3,11,12,6,14,74,16,96),元素个数是10,关键字范围是0~99,如果散列值的容量是100,很明显是一对一不会产生冲突,但是空间利用率此时只有10%,如果容量是10或者20,冲突差生的频率会减少
除留余数法
该散列函数定义为hash(k)=k%p,函数结果范围为0~p-1,图示就是采用这种方法,而p取值为小于散列表长度的最大素数,如散列表长度分别为8,16,128,则对应的p(最大素数)分别为7,13,127
冲突处理
开放定址法
当产生冲突时,开放定址法在散列表内寻找另一个位置存储冲突的元素,如利用线性探查发实现,即设一个元素关键字为k,其散列地址为i=hash(k),若散列表中i位置已存储元素,则产生冲突,探测下一个位置i+1是否为空,。。直到找到一个空位置,但是它的缺陷就是在散列表内处理冲突,使得一个存储地址i可被任意一个元素抢占,这样就破坏了散列函数i=hash(k)的规则
链地址法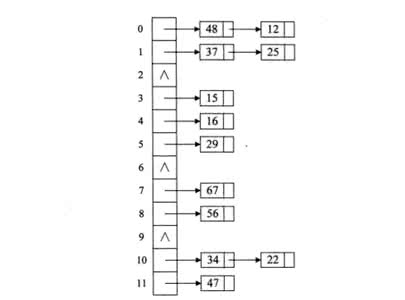
该方法是将多个冲突的元素存储在一条单链表中(称为同义词单链表),如图示
而对链地址法表进行插入、删除、查找等操作主要分两步完成
1.计算元素的散列函数值
2.根据元素的散列函数值,对某一条同义词单链表进行插入、删除和查找操作
规定查找成功的平均查找长度为(根据图示)ASL=(91+32)/12
并且有如下结论:
1.查找操作的时间复杂度为O(m),其中m为一条痛一次单链表的长度,插入操作为O(1),删除操作为O(m)
模拟HashSet类
这里同义词单链表采用单链表